Seamless Cloud Computation & Storage
-- CLOUD COMPUTATIONAL INVESTIGATION --
With CloudyCluster you can easily create HPC/HTC jobs that will run
on-prem or in CloudyCluster on GCP and AWS. You can rely on the familiar look and feel of a standard HPC environment while embracing the capabilities and elasticity of the Cloud. The HPC jobs can be easily configured to support many instance types and any number of memory & CPU configurations. You will always have the latest computational technology at your fingertips.
-- INTERACTIVE RESEARCH COMPUTING --
With the latest release of CloudyCluster, users can now take advantage of the GUI developed by OSC and the cloudyCluster Team. This new inclusion offers non-computer scientists a pathway to cloud-based HPC tools, without having to utilize the CLI. Upload and Download files with a file browser-like interface. You can now: draft job scripts with the built-in Job Script tool, spin-up new computing instances with or without a variety of GPU Acceleration, and have them tear down automatically after your specified work window. The current release includes JupyterLab with Jupyter Notebooks in Python 3 for true interactive computation.
CloudyCluster online documentation-->
Open OnDemand Project-->
-- RESEARCH CLOUD STORAGE --
As part of Google Cloud, AWS, and CloudyCluster you have a vast array of storage technologies available to you. The data can be configured to reside at different storage classes based on age or access frequency. Jobs can be configured to pull the data needed for computation to High Performance Parallel Storage. Let us show you how cost effective storage can be in the cloud when you leverage the full capabilities of Cloud Storage and CloudyCluster.
-- THE HUMAN ELEMENT --
People make all the difference, we want to help you be successful, whether you are a researcher, helping support researchers, or in a leadership role. We are continually creating resources to help you simplify integrating cloud computation and storage with your research processes. The CloudyCluster team offers assistance with knowledge transfer from specific workflows to strategic direction and planning on reducing your time to discovery.
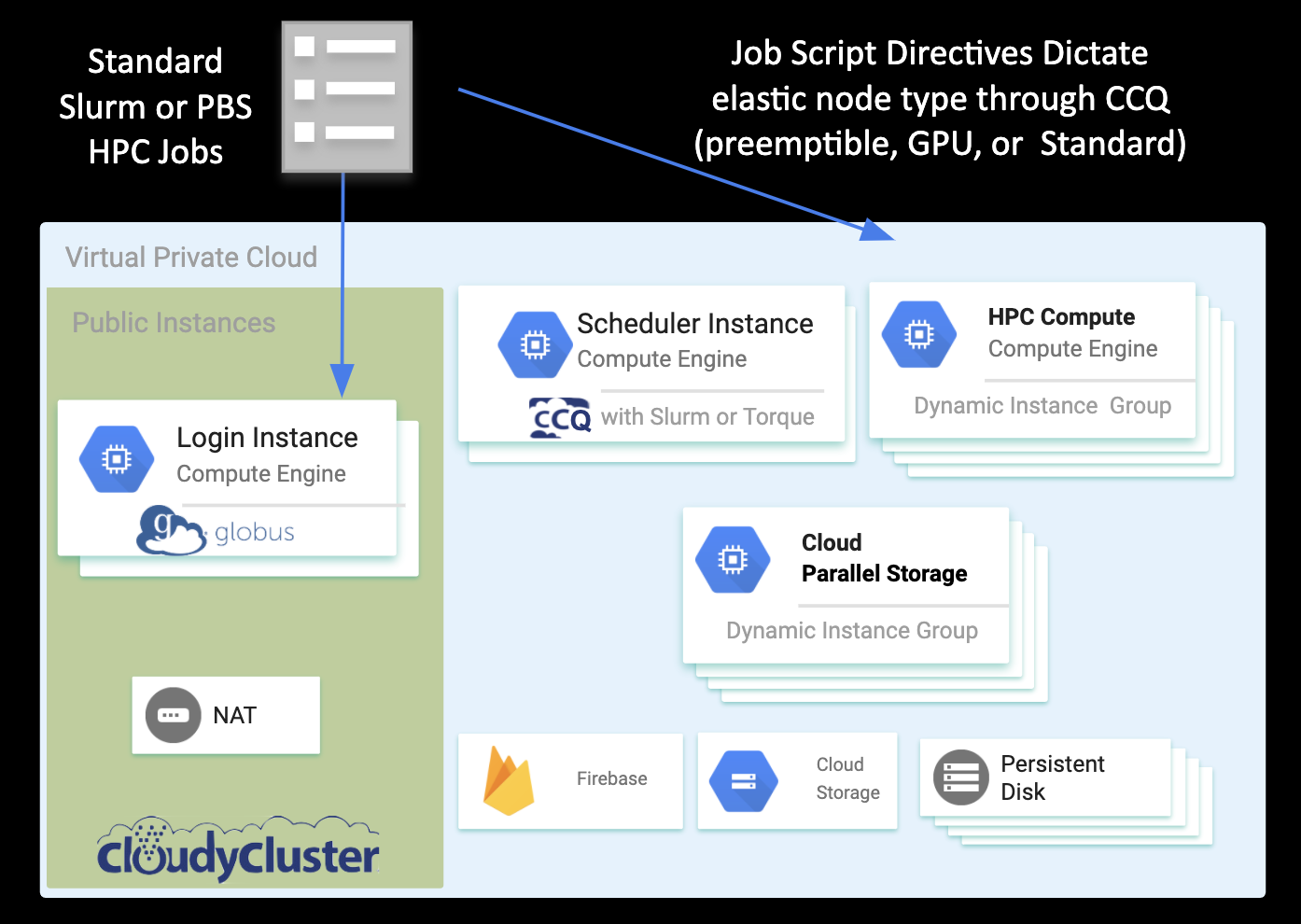
-- GOOGLE CLOUD ARCHITECTURE --
You Create a fully operational & secure computation cluster in minutes, complete with:
Encrypted Storage (GCS, OrangeFS on PD),Compute (standard, preemptible, & GPU), HPC Scheduler (Torque or SLURM with the CCQ Meta-Scheduler). CloudyCluster includes over 300 packages and libraries used in HPC, HTC, & ML workflows. You can also easily customize the base image with your own software as needed.
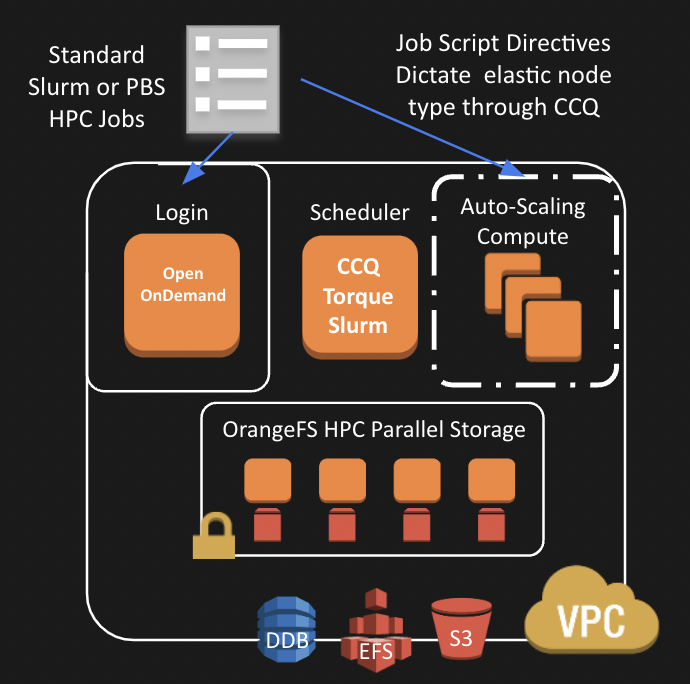
-- AWS ARCHITECTURE --
You Create a fully operational & secure computation cluster in minutes, complete with:
Encrypted Storage (S3, OrangeFS on EBS),Compute (standard, Spot, & GPU), HPC Scheduler (Torque or SLURM with the CCQ Meta-Scheduler). CloudyCluster includes over 300 packages and libraries used in HPC, HTC, & ML workflows. You can also easily customize the base image with your own software as needed.
-- SCALING --